데이터베이스란?
텍스트, 이미지, 파일 등 각종 데이터를 저장하기 위해서 필요한 도구 입니다. 프로젝트를 만들게 되면 여러 데이터들을 따로 보관해야 하고 이러한 보관작업을 도와주는 역할을 한다고 볼 수 있습니다.
데이터베이스는 조직화된 방식으로 데이터를 저장, 관리, 조작하는 시스템 전체를 의미합니다. 사용하고 있는 PC에 저장공간(하드디스크)이 있고 여기에 각종 데이터들을 저장할 수 있는데요, 하드디스크는 파일의 저장 위치, 크기, 접근 권한 등을 관리하는 역할을 합니다만 이를 데이터베이스라고 보진 않습니다. 데이터베이스가 이보다 더 큰 개념으로 구조화된 데이터를 관리하는 시스템 이라고 보시면 됩니다.
이러한 데이터베이스는 사용 용도에 따라서 SQL(Structured Query Language) 또는 NoSQL로 나뉘게 됩니다.
SQL
관계형 데이터베이스라고도 불리우는 SQL은 테이블, 컬럼, 행으로 구성된 구조화된 데이터를 저장하고 관리하는데 주로 사용됩니다. 테이블이나 컬럼과 같은 개념이 다소 생소하시다면 엑셀 구성을 참고하시면 조금 쉽게 이해할 수 있습니다.
예를들어 생활용품을 판매하는 어플리케이션의 데이터를 구성한다고 가정해보겠습니다. 큰 맥락에서 구분해보자면
1. 구매자 회원 정보
2. 판매할 생활용품의 정보
3. 주문정보
이정도로 구분할 수 있겠습니다. Java Spring Framework 에서는 이를 Entity 라고 부르며 해당 Entity가 곧 테이블 입니다.

이해를 돕기위한 그림 예시 입니다. Member, Product, Order은 DB를 구성하는 각 테이블이 됩니다. 첫번째 행 고유ID ... 등 테이블에서 데이터가 저장 될 부분을 구분해둔 것이 컬럼이 됩니다. 데이터를 넣어주게 되면 빈 공간에 맞춰서 데이터들이 쌓이게 됩니다.
PK
고유ID는 테이블의 핵심요소로 PK(Primare Key) 라고 부릅니다. Member 테이블을 예시로 보면 회원 ID 컬럼이 있지만 이는 회원의 로그인이나 기타 다른용도를 위한 저장값일 뿐이고, 테이블 내에서 각 행을 고유하게 식별하고 참조하는 역할을 하는 것은 PK 입니다. PK에는 몇가지 특성이 있습니다.
1. 고유성 : 반드시 테이블 내에 하나의 값만 있어야 합니다.
2. Null 제한 : PK열은 Null을 허용하지 않습니다.
3. 불변성 : PK값을 바꿀 수 없습니다.
저는 Spring 으로 프로젝트를 만들 때 PK값은 항상 숫자를 사용했습니다. JPA에서 AutoIncrease 기능을 제공해줘서 따로 고유ID 값을 넣지 않아도 데이터를 넣을 때 마다 1, 2, 3 ... 이런식으로 자동으로 생성해주는 편리함이 있었습니다.
FK

Order 테이블을 보면 주문자의 ID도 필요하고 상품명도 필요합니다. 그러면 어떤 회원이 주문했고 주문한 상품이 어떤것인지 판별하는 가장 효과적인 방법은 주문한 회원정보는 Member 테이블의 PK에서 가져오고 상품은 Product 테이블의 PK를 가져오는 것입니다. 이 때 Member 테이블의 PK값과 Product 테이블의 PK값이 Order 테이블의 FK(Foreign Key) 가 됩니다. FK역시 몇가지 특성이 있습니다.
1. 참조 무결성 : FK의 값은 참조하려는 테이블의 PK값 중 하나여야 합니다.
2. 관계 형성 : FK를 사용하여 테이블 간의 관계를 형성할 수 있습니다.
3. 참조 무결성 제약 : 만약 Member 테이블의 특정 값이 수정된다면 해당 테이블을 참조하고 있는 Order 테이블의 Member테이블 FK 값이 수정됩니다.
쿼리문
데이터베이스는 데이터를 생성, 수정, 조회, 삭제 기능을 제공합니다. 이러한 기능들을 사용하려면 DB에 명령어를 전달해줘야 하는데요, 이 명령어를 쿼리문 이라고 합니다. 쿼리문은 대표적으로
INSERT : 데이터 삽입
UPDATE : 데이터 수정
SELECT : 데이터 조회
DELETE : 데이터 삭제이렇게 4종류를 기본으로 구성됩니다.
보통 쿼리문을 공부하게 된다면 중점적으로 배우는 문장이 SELECT 문장 입니다. 등록, 수정, 삭제는 로직이 크게 복잡하지 않아서 성능에도 큰 영향을 끼치지 않지만 방대한 데이터를 조회하는 것은 많은 시간과 자원을 소비하는 영역이고 그에따라 어떤 로직을 적용하느냐에 따라 성능이 달라지기 때문입니다.
SELECT 쿼리문은 수행 순서가 있습니다.
1. FROM : 각 테이블을 확인합니다.
2. ON : 후술할 JOIN 의 조건을 확인합니다.
3. JOIN : 둘 이상의 테이블을 연결하여 관련된 데이터를 함께 조회합니다.
4. WHERE : 특정 조건을 만족하는 행만 선택합니다.
5. GROUP BY : 특정 열을 기준으로 그룹화 합니다.
6. HAVING : GROUP BY절이 쿼리에 있다면 HAVING절로 그룹에 대한 조건을 지정합니다.
7. SELECT : 가져올 열(컬럼)을 지정합니다. SELECT절에 표현된 식이 가장 마지막으로 적용됩니다.
8. DISTINCT : 중복 된 결과를 삭제합니다.
9. ORDER BY : 데이터를 오름차순 또는 내림차순으로 정렬합니다.
10. LIMIT / OFFSET : 결과를 제한하고 페이지네이션 처리를 합니다.
SELECT member_id, member_name, order_id, order_quantity
FROM members
JOIN orders ON members.member_id = orders.member_id;쿼리문의 예시 입니다. Member 테이블과 Order 테이블을 member_id를 기준으로 JOIN 하여 결과를 가져옵니다. 해당 쿼리문을 실행하게 된다면 member.member_id 와 orders.member_id 가 일치하는 데이터만 결과에 포함됩니다.
여기서 눈여겨볼 명령어는 'JOIN' 문 입니다. 해당 문은 LEFT JOIN, RIGHT JOIN, INNER JOIN, OUTER JOIN 등 여러 조건을 걸어서 데이터를 조회할 수 있습니다.

LEFT JOIN과 RIGHT JOIN의 예시 입니다. 개인적으로 가장 헷갈리는 부분인데 FROM의 기준을 어디에 둬서 LEFT 혹은 RIGHT를 사용하느냐에 따라 결과가 달라집니다.
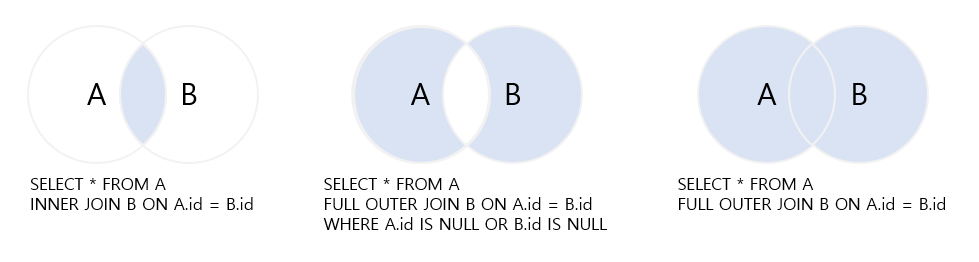
INNER JOIN과 OUTER JOIN의 예시 입니다. 단 버전에 따라 FULL OUTER JOIN을 제공하지 않는 경우도 있어서 이때는 LEFT JOIN 또는 LEFT OUTER JOIN, RIGHT JOIN 또는 RIGHT OUTER JOIN 을 적절하게 사용하여 데이터를 찾을 수 있습니다.
SQL을 사용하는 경우
데이터의 일관성과 안전성이 요구되는 어플리케이션이라면 거의 다 적용이 되었다고 볼 수 있습니다. 특히 금융분야처럼 트랜잭션 처리가 필수적으로 이뤄져야 하는 어플리케이션이라면 대부분 사용하고 있다고 볼 수 있습니다.
일반적으로 MySQL, Oracle, Microsoft SQL Server, PostgreSQL, MariaDB 등의 프로그램을 사용합니다.
다만 대규모 데이터에 대한 저장과 확장성이 중시될 경우 NoSQL 데이터베이스인 Redis, MongoDB, Cassandra, Elasticsearch 등을 활용하기도 합니다.
'개발 > 지식' 카테고리의 다른 글
| 네트워크에 대한 이해 - 네트워크 구성 기술 (UDP, PORT, URL, DNS) (0) | 2023.05.17 |
|---|---|
| 네트워크에 대한 이해 - 네트워크 구성 기술 (TCP/IP) (0) | 2023.05.16 |
| 데이터베이스에 대한 기본적인 이해 (NoSQL) (0) | 2023.05.16 |
| 가비지 컬렉션(Garbage Collection)의 작동원리 (0) | 2023.05.09 |